Step 1: Selecting the Base Model
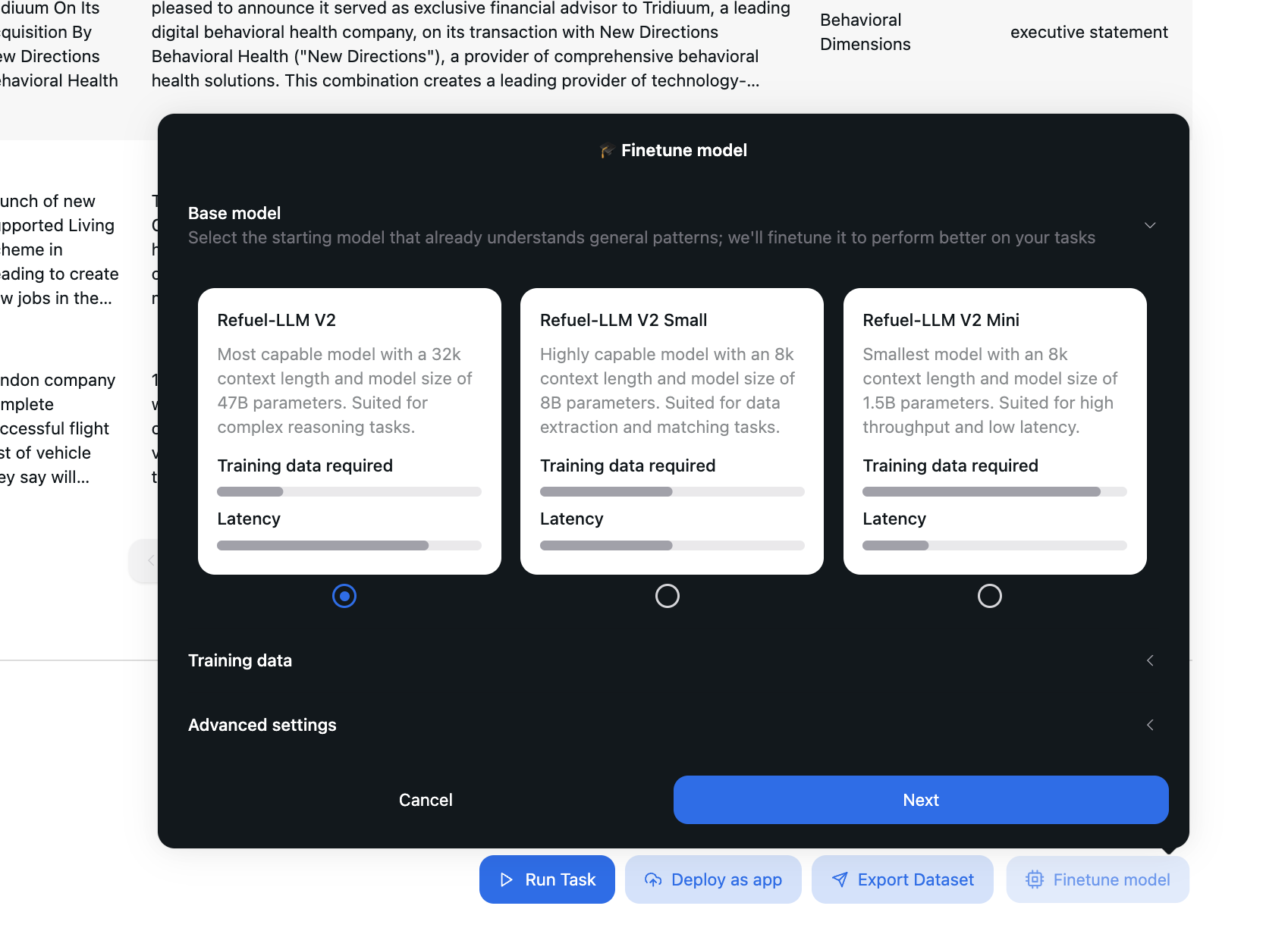
Refuel-LLM V2
Refuel-LLM V2
Most capable model with a 32k context length and a 47B parameter size.
Suited for complex reasoning tasks where detailed understanding and large input/output processing are required.Pros:
Handles long context inputs effectively (e.g., large documents or conversations).
Best choice for tasks requiring high-level reasoning and accuracy.
High parameter count allows for nuanced understanding and generation.Cons:
Requires more training data to fine-tune effectively.
Higher latency due to its size, making it slower for real-time applications.
More resource-intensive (computational cost and time).
Refuel-LLM V2 Small
Refuel-LLM V2 Small
A highly capable model with an 8k context length and a 8B parameter size.
Optimized for tasks such as data extraction and pattern matching.Pros:
Faster latency compared to Refuel-LLM V2, making it more efficient for smaller tasks.
Requires less training data and computational resources.
Well-suited for structured tasks like entity recognition or data classification.Cons:
Lower capacity for handling longer context inputs (e.g., long documents).
Limited reasoning capability compared to larger models.
May struggle with complex tasks requiring high precision.
Refuel-LLM V2 Mini
Refuel-LLM V2 Mini
Smallest model with an 8k context length and a 1.5B parameter size.
Designed for high throughput and low latency tasks.Pros:
Extremely fast and efficient, making it ideal for real-time use cases (e.g., chatbots, low-latency inference).
Requires minimal computational resources for training and deployment.
Best choice when performance speed is critical, or large-scale deployment is needed.Cons:
Limited capacity for reasoning and complex tasks due to its small parameter size.
Performs less effectively on tasks involving nuanced language understanding.
Handles only moderate context lengths, making it unsuitable for tasks with extensive inputs.
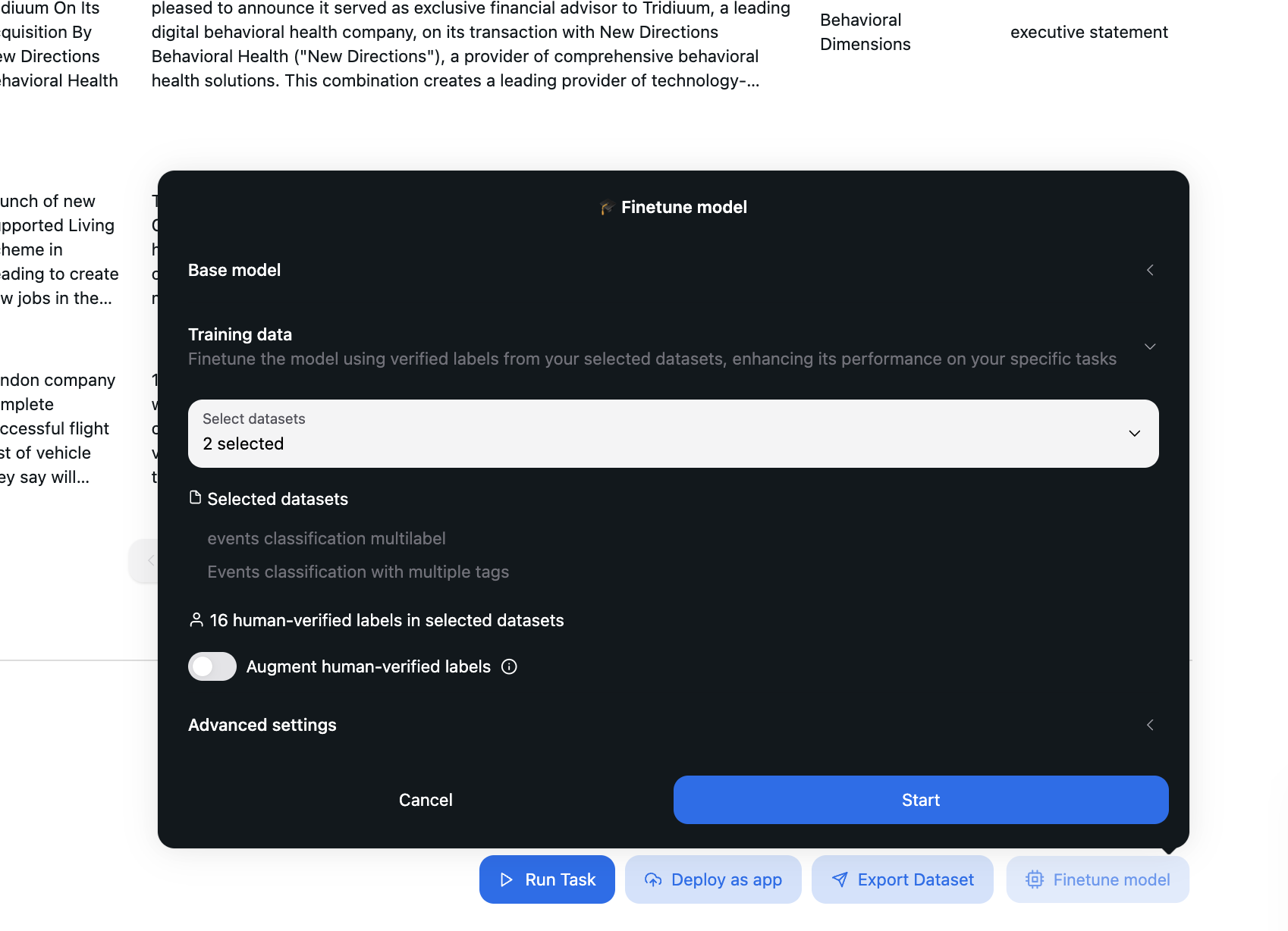
Step 2: Selecting Training Data
Step 3: Configuring Advanced Settings
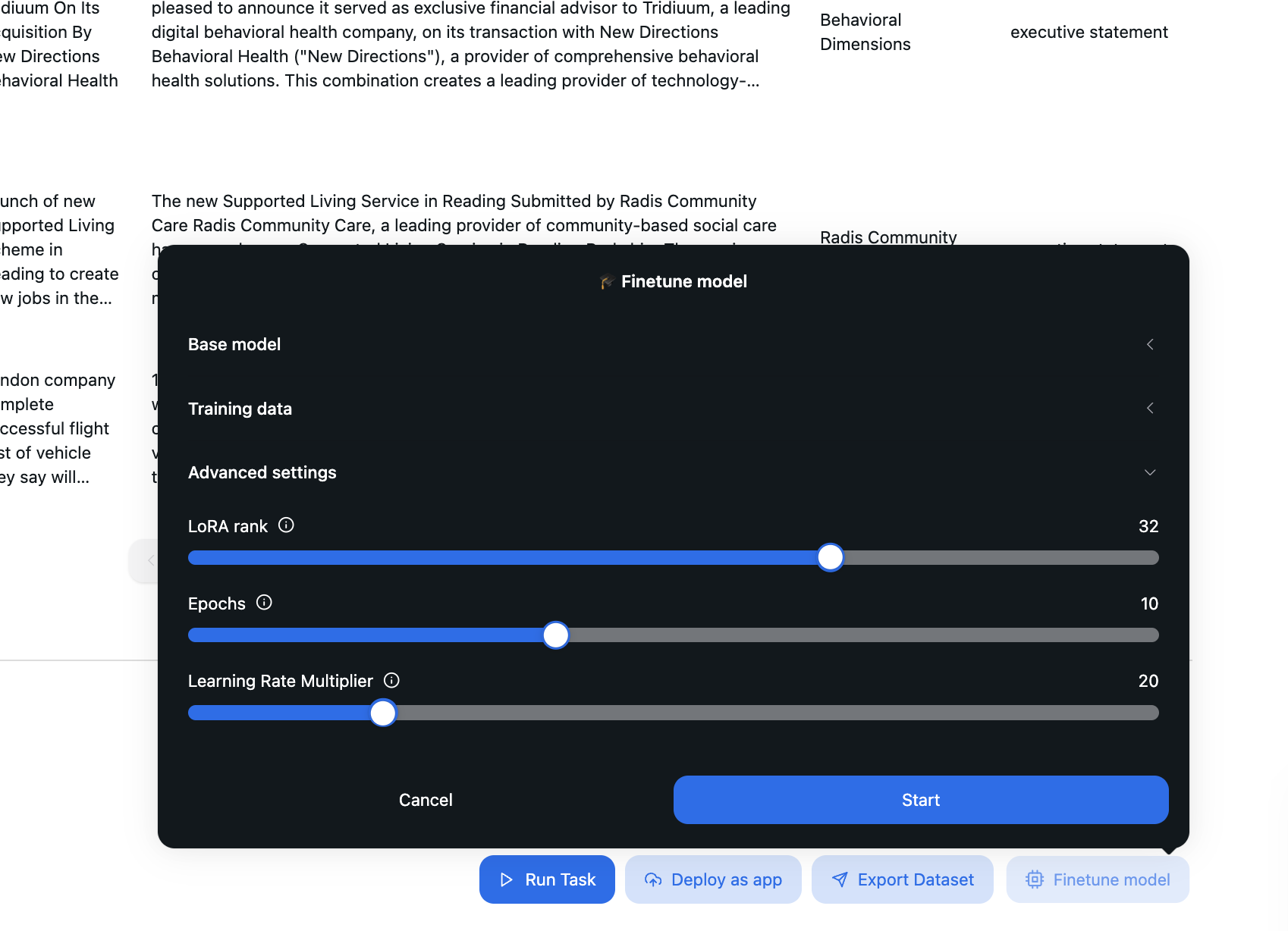
LoRA Rank
LoRA Rank
LoRA (Low-Rank Adaptation) is a technique that reduces the number of trainable parameters by introducing low-rank matrices during fine-tuning.
The LoRA rank determines the rank (or size) of these low-rank matrices. Higher values increase the capacity of the fine-tuning process, allowing the model to learn more complex patterns.A higher LoRA rank improves the model’s ability to adapt to your training data, which can result in better fine-tuning performance.
A lower LoRA rank reduces computational cost and training time but may sacrifice some accuracy.A rank of 32 (as shown in the slider) indicates a balance between complexity and efficiency.Recommendation: Increase the rank for tasks requiring more complex learning (e.g., nuanced patterns or long sequences). Decrease it for simpler tasks to save resources.
Epochs
Epochs
An epoch represents one complete pass of the training data through the model during fine-tuning. The number of epochs determines how many times the model sees and learns from the training data.A higher number of epochs allows the model to learn more from the data, improving its performance—up to a point. If the number of epochs is too high, the model may overfit the training data, reducing its performance on unseen tasks.
A lower number of epochs speeds up the training but may result in underfitting.10 epochs (as shown in the slider) is a reasonable default for balanced learning. Adjust this based on the dataset size and complexity.Recommendation: For smaller datasets, use more epochs to ensure the model learns enough. For large datasets, fewer epochs are usually sufficient.
Learning Rate Multiplier
Learning Rate Multiplier
The learning rate controls how much the model’s weights are updated with each training step.
The learning rate multiplier scales the base learning rate, allowing you to fine-tune its impact.A higher learning rate speeds up training but may cause the model to converge too quickly, potentially missing optimal solutions.
A lower learning rate makes training slower but ensures more gradual and stable convergence.A multiplier of 20 (as shown in the slider) indicates a moderate learning rate. This should work for most datasets but could be adjusted for more delicate training.Recommendation: Start with a moderate multiplier. If the model fails to converge or produces poor results, reduce the learning rate. If training is too slow or the model seems stuck, increase the multiplier.